This article discusses all possible alternatives for getting the first or last records from each mysql group.
Consider this sample table ( user_log ) for example:
| Table ( user_log ) | |||
| id | user_id | first_name | last_name |
|---|---|---|---|
| 1 | 1 | fname1.1 | lname 1.1 |
| 2 | 1 | fname1.2 | lname 1.2 |
| 3 | 1 | fname1.3 | lname 1.3 |
| 4 | 1 | fname1.4 | lname 1.4 |
| 5 | 2 | fname2.1 | lname 2.1 |
| 6 | 2 | fname2.2 | lname 2.2 |
| 7 | 2 | fname2.3 | lname 2.3 |
| 8 | 2 | fname2.4 | lname 2.4 |
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE IF NOT EXISTS `user_log` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) NOT NULL, `first_name` varchar(255) NOT NULL, `last_name` varchar(255) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1; |
|
1 2 3 4 5 6 7 8 9 10 |
INSERT INTO `user_log` (`id`, `user_id`, `first_name`, `last_name`) VALUES (1, 1, 'fname1.1', 'lname1.1'), (2, 1, 'fname1.2', 'lname1.2'), (3, 1, 'fname1.3', 'lname1.3'), (4, 1, 'fname1.4', 'lname1.4'), (5, 2, 'fname2.1', 'lname2.1'), (6, 2, 'fname2.2', 'lname2.2'), (7, 2, 'fname2.3', 'lname2.3'), (8, 2, 'fname2.4', 'lname2.4'); |
In this table, there are 8 records of 2 users [user_id = 1, 2].
We want a query to get either first or last record in each user_id group. i.e. ( first or last records with user_id = 1, 2 ).
Here are possible solutions, their “Explain” statements and performance matrix (every query executed 3 times to check timing) to check which query would be best according to your requirements.
Query 1
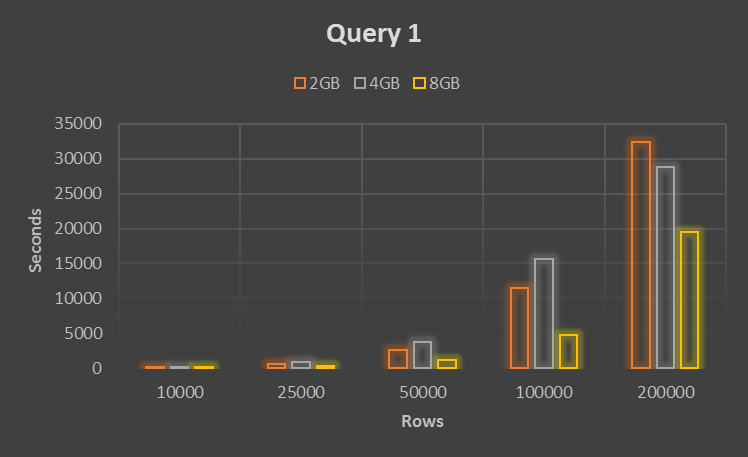
Query 1 shows the conceptually simplest approach which is querying the table with id where id is in sub query which returns the maximum id group by user_id. Explain statement shows the query is executed in two parts as PRIMARY and DEPENDENT SUBQUERY iterating whole table 2 times.
As we can see in the performance matrix below the Query 1 is time consuming and hence not recommend.
|
1 2 3 4 5 6 7 8 |
SELECT * FROM user_log where id IN ( SELECT max(id) FROM `user_log` group by user_id ); |
| SQL Result | |||
| id | user_id | first_name | last_name |
|---|---|---|---|
| 4 | 1 | fname1.4 | lname 1.4 |
| 8 | 2 | fname2.4 | lname 2.4 |
| Explain Result | |||||||||
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | user_log | ALL | NULL | NULL | NULL | NULL | 8 | Using where |
| 2 | DEPENDENT SUBQUERY | user_log | ALL | NULL | NULL | NULL | NULL | 8 | Using temporary; Using filesort |
| Performance Matrix* | |||
| Rows | 2GB | 4GB | 8GB |
|---|---|---|---|
| 10000 | 99.24 | 152.7567 | 46.21667 |
| 25000 | 617.7533 | 929.76 | 295.9333 |
| 50000 | 2646.973 | 3742.683 | 1212.503 |
| 100000 | 11447.51 | 15600.39 | 4719.04 |
| 200000 | 32400 | 28800 | 19544.14 |
| *Time is in seconds | |||
| Performance Matrix Chart |
 |
| Pros | Cons |
|
|
| Conclusion : NOT RECOMMENDED | |
Query 2
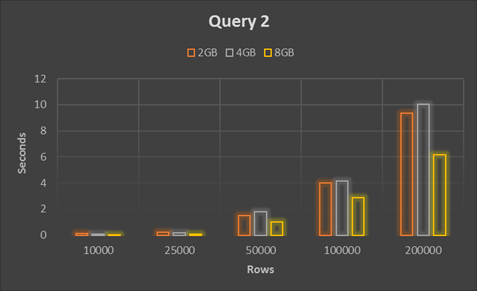
Query 2 shows the approach where we query the table with the help of derived table t_max. Explain statement shows the query is executed in two parts as PRIMARY and DERIVED iterating whole table 2 times.
As we can see in the performance matrix below the Query 2 is better than Query 1 but still time consuming and hence not recommended.
|
1 2 3 4 5 6 7 8 |
SELECT * FROM ( SELECT max(id) as high, user_id, first_name, last_name FROM user_log GROUP BY user_id DESC, id DESC ) as t_max GROUP BY t_max.user_id; |
| SQL Result | |||
| id | user_id | first_name | last_name |
|---|---|---|---|
| 4 | 1 | fname1.4 | lname 1.4 |
| 8 | 2 | fname2.4 | lname 2.4 |
| Explain Result | |||||||||
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | ALL | NULL | NULL | NULL | NULL | 8 | Using temporary; Using filesort | |
| 2 | DERIVED | user_log | ALL | NULL | NULL | NULL | NULL | 8 | Using temporary; Using filesort |
| Performance Matrix* | |||
| Rows | 2GB | 4GB | 8GB |
|---|---|---|---|
| 10000 | 0.106667 | 0.06 | 0.03 |
| 25000 | 0.203333 | 0.173333 | 0.08 |
| 50000 | 1.516667 | 1.773333 | 1.01 |
| 100000 | 4.013333 | 4.16 | 2.896667 |
| 200000 | 9.356667 | 10.03333 | 6.173333 |
| *Time is in seconds | |||
| Performance Matrix Chart |
 |
| Pros | Cons |
|
|
| Conclusion : NOT RECOMMENDED | |
Query 3
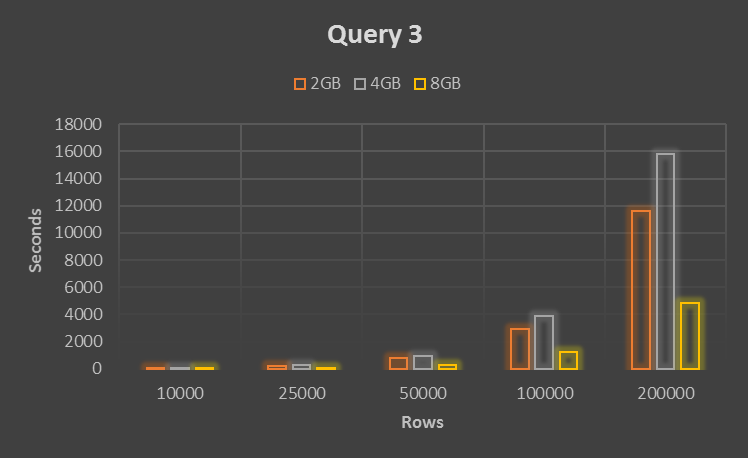
Query 3 shows the approach of Joins. Explain statement shows the query is executed in two parts as SIMPLE and SIMPLE iterating whole table 2 times.
As we can see in the performance matrix below the Query 3 too time consuming so not recommended.
|
1 2 3 4 5 6 7 8 |
SELECT MAX(u1.id) as id, u1.user_id, u1.first_name, u1.last_name FROM user_log u1 LEFT JOIN user_log u2 ON u1.user_id = u2.user_id AND u1.id < u2.id WHERE u2.id IS NULL GROUP BY u1.user_id; |
| SQL Result | |||
| id | user_id | first_name | last_name |
|---|---|---|---|
| 4 | 1 | fname1.4 | lname 1.4 |
| 8 | 2 | fname2.4 | lname 2.4 |
| Explain Result | |||||||||
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | u1 | ALL | NULL | NULL | NULL | NULL | 8 | Using temporary; Using filesort |
| 1 | SIMPLE | u2 | ALL | PRIMARY | NULL | NULL | NULL | 8 | Using where; Not exists |
| Performance Matrix* | |||
| Rows | 2GB | 4GB | 8GB |
|---|---|---|---|
| 10000 | 30.22667 | 39.01333 | 12.23667 |
| 25000 | 188.9967 | 240.8033 | 80.59 |
| 50000 | 756.0533 | 965.7833 | 308.7467 |
| 100000 | 2946.127 | 3916.707 | 1195.153 |
| 200000 | 11581.11 | 15778.77 | 4821.28 |
| *Time is in seconds | |||
| Performance Matrix Chart |
 |
| Pros | Cons |
|
|
| Conclusion : NOT RECOMMENDED | |
Query 4
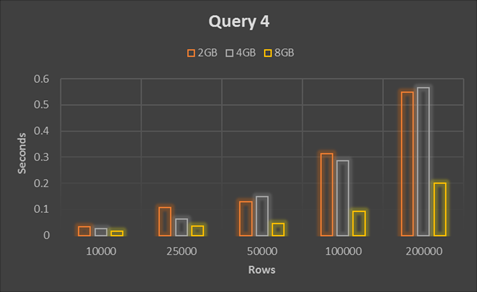
Query 4 shows the approach of Joins with derived table. Explain statement shows the query is executed in three parts as PRIMARY, PRIMARY and DERIVED but the table is not iterated 2 times here.
As we can see in the performance matrix below the Query 4 is very time efficient so it is recommended.
|
1 2 3 4 5 6 7 8 9 |
SELECT u1.* FROM user_log u1 INNER JOIN ( SELECT user_id, MAX(id) AS mId FROM user_log GROUP BY user_id ASC ) u2 ON u1.user_id = u2.user_id AND u1.id = u2.mId; |
| SQL Result | |||
| id | user_id | first_name | last_name |
|---|---|---|---|
| 4 | 1 | fname1.4 | lname 1.4 |
| 8 | 2 | fname2.4 | lname 2.4 |
| Explain Result | |||||||||
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | ALL | NULL | NULL | NULL | NULL | 2 | ||
| 1 | PRIMARY | u1 | eq_ref | PRIMARY | PRIMARY | 4 | u2.mId | 1 | Using where |
| 2 | DERIVED | user_log | ALL | NULL | NULL | NULL | NULL | 8 | Using temporary; Using filesort |
| Performance Matrix* | |||
| Rows | 2GB | 4GB | 8GB |
|---|---|---|---|
| 10000 | 0.033333 | 0.026667 | 0.016667 |
| 25000 | 0.106667 | 0.063333 | 0.036667 |
| 50000 | 0.13 | 0.15 | 0.046667 |
| 100000 | 0.313333 | 0.286667 | 0.093333 |
| 200000 | 0.55 | 0.566667 | 0.2 |
| *Time is in seconds | |||
| Performance Matrix Chart |
 |
| Pros | Cons |
|
|
| Conclusion : RECOMMENDED | |
Query 5
Query 5 shows the approach of Simple query and then string processing on columns to get the result we want. Explain statement shows the query is executed in only one part as SIMPLE so the table is iterated only once.
As we can see in the performance matrix below the Query 5 is also time efficient compared with Query 1, Query 2 and Query 3 so it is recommended.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT SUBSTRING_INDEX( GROUP_CONCAT(DISTINCT id ORDER BY id DESC), ',', 1 ) as id, user_id, SUBSTRING_INDEX( GROUP_CONCAT(DISTINCT first_name ORDER BY id DESC), ',', 1 ) as first_name, SUBSTRING_INDEX( GROUP_CONCAT(DISTINCT last_name ORDER BY id DESC), ',', 1 ) as last_name FROM user_log GROUP BY user_id ORDER BY id ASC; |
| SQL Result | |||
| id | user_id | first_name | last_name |
|---|---|---|---|
| 4 | 1 | fname1.4 | lname 1.4 |
| 8 | 2 | fname2.4 | lname 2.4 |
| Explain Result | |||||||||
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | user_log | ALL | NULL | NULL | NULL | NULL | 8 | Using temporary; Using filesort |
| Performance Matrix* | |||
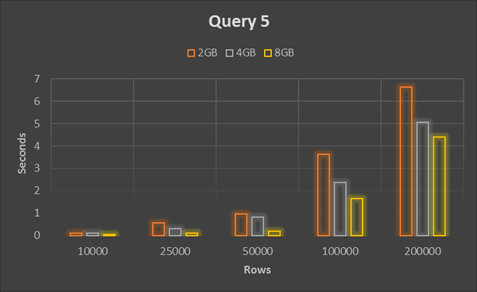
| Rows | 2GB | 4GB | 8GB |
|---|---|---|---|
| 10000 | 0.113333 | 0.113333 | 0.043333 |
| 25000 | 0.55 | 0.293333 | 0.103333 |
| 50000 | 0.963333 | 0.81 | 0.196667 |
| 100000 | 3.64 | 2.366667 | 1.65 |
| 200000 | 6.63 | 5.053333 | 4.406667 |
| *Time is in seconds | |||
| Performance Matrix Chart |
 |
| Pros | Cons |
|
|
| Conclusion : RECOMMENDED | |
As we can see from the data matrix Query 4 and Query 5 are best suited to handle this problem.
The performance of this queries can very from data sets to data sets, here the data set taken is symmetrical (each user wise 4 rows), if data is asymmetrical these result will slightly differ, but it is beyond doubt that Query 4 and Query 5 will outperform every other query.
Common mistake in using MAX:
A simple mistake Developers make in this type of queries is using MAX function to get the last records from each group. Let’s see by example.
consider these 2 queries
SELECT max(id),user_id,first_name,last_name FROM user_log group by user_id DESC
SELECT max(id),id,user_id,first_name,last_name FROM user_log group by user_id DESC
Most developers just use query 1 thinking, MAX(id) will give them the row with id = MAX(id) which is wrong.
You can catch the problem if you run the 2nd query with id in column. You can clearly see the MAX(id) is 8 and id is returning 5, so the result is wrong. And unlike in our example if you do not have different data in columns other than id [first_name, last_name], it is difficult to catch this problem.
So, let me clear one misconception that MAX(id), is a function that returns the maximum of the rows in that column, Using MAX(id) does not return maximum id of rows in the query result.
Structural changes:
Let’s discuss what structural changes we could have done to improve the performance.
So basically we have an option of adding a column that returns the latest record, for each group last row(or first depend on your query) added a flag last= 1last= 0
1. By Trigger
2. By Manual programming changes
Which ever works for you, but if you can afford to add an column then it would largely simplify your query if not you can always use Query 4 or Query 5.
Leave a Reply